

My background is as a developer and a security professional, so when I had to learn system design I approached it from that perspective. While I was familiar with many of these concepts, I decided that I had to learn it in depth and in earnest. Now that I know more, I’m convinced that every developer and every security professional should understand these concepts. For all of you who are like me and want to learn more, here’s an overview to help you think about system design, coming at it from a mindset of application security.
If you are a developer new to system design, this will introduce you to the topic while sneakily adding a few application security concepts.
If you are a security professional, this will serve as a framework and mental model to help you think about system design. It will make you more effective in how you can help development teams building modern, highly-scalable, cloud-first systems.
You don’t need to read all of the sections below. Instead pick the ones most applicable to your system, to start a meaningful conversation with other engineers and architects about security.
Modern system design is all about performance, consistency, and reliability at scale.
When you need to understand an existing system, or design a new system, start with a set of clarifying questions:
- What are the use cases?
- How many users are expected on the system over the next year?
- How much data is the system expected to process and persist?
- Are there constraints around transactions, latency, memory, or data storage?
- What are the security requirements and customer expectations?
- What are the assets that need protection?
- What attacks that have been seen in the past on this system or systems like it?
This will give you an understanding of the shape of the system - everything else you learn slots into the answers to these questions.
Next dig into the key features:
- Expected usage of each feature?
- What roles are involved and how is authorization handled?
- How does that translate into requests per second?
- How does that translate into data storage?
- Reads vs writes?
Some of the features will be represented as UI, some as APIs. Where there are APIs understand the most important API definitions. For instance:
- postComment(userID, comment_text, user_location, timestamp)
Right away you may have some questions or concerns regarding what could go wrong. Looking at the above API, I’d want to know:
- How is userID generated, authenticated, and protected?
- Is the comment_text validated in any way?
- How is the comment_text used downstream? For instance, will it be echoed to HTML and does it need to be encoded before use?
- Is user_location necessary, given the potential privacy concerns? If so, how is the data used and how is it protected?
So even with a single API definition, you can start to dig into details and begin to surface security concerns. Any entry point is a possible way to start a security discussion that can bear fruit.
Next, it’s useful to see a high level architecture diagram. Some systems already have this in place, but many do not. If it doesn’t exist, create it. It is easier to have a conversation with an architect to build a diagram together than it is to ask for one and wait, hoping that they will get around to it.
A diagram doesn’t have to be complex to be useful. Just enough to get a sense of what’s going on, understand trust boundaries, and start to see sources of input.
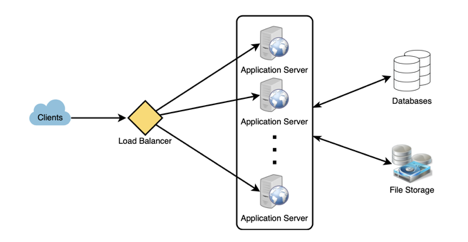
It can be very useful at this point to ask about tradeoffs. Every system has them. What difficult decisions had to be made and what were the pros and cons. Sometimes this is documented, but usually it’s in someones head. Try to understand that, because it’ll give you a sense for what the system was optimized for and what’s less important. It also may give you some hints about weaknesses from a security point of view.
From a system design point of view, the following questions are useful:
- Are there bottlenecks? For instance a lot of read requests with few writes that may indicate the need for primary/secondary replication. Or a set of users that generate abnormal traffic that may indicate the need to memcache the most-used data.
- Are there single points of failure?
- What happens if the database goes down?
- What happens if the web server goes down?
- What happens if transaction quantity increases dramatically?
- Where do load balancers sit in the architecture?
- How does the load balancer distribute evenly?
- What if the load balancer goes down?
- Where does request throttling happen?
- Can you ban specific IPs, blocks, or regions if under attack?
The next layer to think about is the database.
- What are the key tables and what information do they hold? This can give insight into the primary objects that are important in this system, for instance:
- User: UserID, Name, Email, DoB, CreationData, LastLogin
- Comment: CommentID, Content, CommentLocation, NumberOfReads, TimeStamp
- Is the database NoSQL or SQL?
- This will tell you if the data model is based on a complex relational strategy or a denormalized strategy focused on rapid access.
- Although this is not always true, since a SQL database can be used with denormalized data and a NoSQL database can just push the joins into the code. But if either of these cases are true, it’s worth understanding why those decisions were made.
- How is data indexed; what performance characteristics are you expecting from each table?
- Do you have cached or materialized views that may store sensitive data?
Finally, it’s time to dig into the decisions made around scalability. This is really the meat of system design and it’s worth understanding each strategy that comes into play:
- Scale vertically by using more powerful servers.
- Scale horizontally by using a larger number of servers.
- Use load balancing to spread load across redundant servers. This can be done at each layer.
- Use Replication to scale reads, while adding redundancy.
- Partition or shard the database to scale horizontally for both reads and writes but this adds complexity and reduces redundancy.
- In memory caching can be used to improve performance for data that is going to be re-used. The key questions are: which data do you want to cache, how large should the cache be, and how will the data be expired out of the cache? For instance:
- Could cache objects returned by queries (e.g. the hash is record index).
- Could cache actual query results (e.g. hash is query string).
- Could cache an index into db to make lookups faster.
- What happens if the cache is destroyed or corrupted?
- Asynchronous operations should be used for slow tasks such as pre-processing dynamic data into static data, or to serve a long user-request. This doesn’t necessarily reduce processing time but it increases the user’s perception of system responsiveness. These still need to be protected with the same Authentication, Authorization, Session and data security standards as other synchronous operations.
There are many other key concepts related to system design that are important to understand in order to get a handle on modern architectures. The most important are collected below.
System Design Concepts
Asynchronism
- Preprocess
- Do the work ahead of time and have the resource ready when the user asks for it.
- For instance, turn dynamic content into static content - on a regular basis, render the pages into static files and store them locally to be served up.
- Job/Message Queue
- Send a time consuming job into a job-queue then tell the users it’s being worked on and will be ready later.
- User isn’t blocked from using the site in other ways while the work is being done.
Caching
- File-based
- Pre-process dynamic content to static content and serve that up.
- Downside is that layout changes are harder because you need to re-process all the content.
- Craigslist does this, for instance.
- Memory-based
- Query Cache (e.g. MySQL)
- The query and its results are cached so that the next time that query is executed, the response comes from memory.
- The query is the key in a key/value pair.
- Hard to know when data is updated in DB but not in cache.
- Cached Objects
- Store the retrieved db data as a class object and then place in cache.
- Makes it easier to expire the entire object as needed or as data changes.
- Objects can be assembled from the DB on multiple threads to improve performance further.
- Memcached
- Key-Value store, strings only.
- Query the cache and if data is there it’ll be retrieved, otherwise it’ll be pulled from db into cache and retrieved.
- When full, old cached data is removed FIFO, so oldest is garbage collected.
- Scales well vertically because it is multi-threaded.
- Redis
- Key-Value store, various data types.
- More expiration options.
- Non-volatile, stores on disk as well.
- Scales well horizontally because it is single-threaded.
- You can also create your own cache in code.
- Query Cache (e.g. MySQL)
- Good stuff to cache: User sessions; Fully rendered pages; Activity streams; relationships between users.
Containers
- Containers are VM-like OS virtualization blocks.
- They can be used to run micro services.
- Can run on any infrastructure, computer, cloud.
- Can be assembled into more complete systems using CloudFormation, Kubernetes or similar.
- Everything needed (except for the shared operating system on the server) to run the application is packaged inside the container object: code, run time, system tools, libraries and dependencies.
- Examples
- Docker
- AWS Fargate
- Google Kubernetes - used with Docker to managed containers at scale
- Amazon ECS
Hashing
- Hashing is a useful for caching objects for quick lookups.
- Since hashing objects can result in collisions, there needs to be a mechanism for handling. You could detect and generate another hash, or if that is turning into a performance bottleneck, create a keystore by pre-generating hashes and use them as needed.
- Hashing is also used to protect passwords, although cryptographically secure hashes must be used in that case. Don’t encrypt passwords, as that adds risk of the password being uncovered.
Load Balancing
- Options
- Use DNS entries, in which case requests will be routed round-robin by DNS server. Often used to balance between sets of load balancers as well.
- This may lead to imbalance because sessions will stick per server (DNS caching) and some sessions will require more work to serve than others.
- Use a load balancer in front of the requisite servers and use round robin strategy.
- May lead to imbalance for same reasons as above.
- Now you need to manage sessions since otherwise requests will hit different servers behind the load balancer. To solve this you can:
- Manage sessions on a database server at the load balancer layer or on the load balancer itself.
- OR load balancer can track which server each client hit first (sessionID in cookie) and future requests on that server (similar to DNS caching).
- Load balancer could query servers on load and pick least busy.
- This can get complicated since it requires a query API between load balancer and the servers as well as logic to make the right choice.
- Have a server per resource type (images, video, static content, dynamic content).
- This may lead to imbalance.
- It doesn’t help with redundancy.
- So you may still need to load balance on servers that take too much load
- Use DNS entries, in which case requests will be routed round-robin by DNS server. Often used to balance between sets of load balancers as well.
- Load balancing can also be done as a service (e.g. Amazon Elastic Load Balancer) or as hardware (e.g Citrix or F5).
Microservices
- Microservices give the freedom to break an application into services that are independently deployable (team, language, tooling, etc).
- Benefits of microservices:
- Small teams of developers can work more nimbly than large teams.
- An application will still function if part of it goes down because microservices allow for spinning up a replacement.
- Meeting demand is easier when microservices only have to scale the necessary components.
- The individual components of microservices can more easily fit into continuous delivery pipelines.
- Microservices pair well with other dynamic and scalable technologies, such as Kubernetes and Serverless technology
- This very heterogeneity can make security more complicated, however.
- The solution is:
- Traceable. Make it easy to see all the component parts. Integrate security into the developer’s workflow. Automate as much as possible.
- Continuously Visible. Don’t rely on surveys, spreadsheets, dashboards. Automate risk ranking for services based on dependencies, Internet exposure, assets involved. Focus effort on highest risks services.
- Compartmentalized. Reduce attack surface. Reduce the need to move sensitive data around (e.g. Token Vault).
- Stateless microservices handle requests and serve up responses only.
- Stateful microservices require storage to run since they maintain state.
- Example technologies:
- RESTful APIs to communicate via HTTP(S)
- Redis for data storage. Single threaded so you avoid locks.
- Prometheus for monitoring.
- RabbitMQ for message/task queueing.
- AWS Lambda for infrastructure-less running of microservices on demand.
NoSQL
- Doesn’t require normalized data.
- Improves performance because:
- Can be optimized for read, write, or data consistency as the business demands.
- Lack of joins, although joins may still need to be done in code.
- NoSQL can make sense when there is a lack of relationships or to enforce a denormalization strategy.
- SQL may make sense because it is widely used, mature, has clear scaling paradigms (sharing, master/slave, replication), and is used by FB, Twitter, Google. It can be as fast as NoSQL on index lookups (no joins).
Partitioning
- Don’t partition/shard unless you need to since it adds significant complexity.
- Shard if your working set is too large to fit in memory or your database can’t keep up with write volume.
- Types:
- Vertical
- DB is partitioned by feature (user profiles, messages, etc).
- Or by region (e.g. Harvard vs MIT in early Facebook days).
- Key-based
- Could be on a simple key, like usernames alphabetical, but the partitions could be uneven.
- Hash-based is to allocate N servers then put data on mod(key, n) server.
- If you add a server, the data will need to be re-allocated which is expensive.
- Directory-based
- Create a lookup table for where the data can be found.
- Servers can be added easily, but the lookup can be a bottleneck and single point of failure.
- Vertical
- What if there is a hot DB partition issue?
- Change the key for consistent hashing so load is distributed more evenly.
- Downsides of partitioning:
- Joins across servers are too slow - must join in code.
- Data integrity across servers can get tricky - must be enforced in code.
- Rebalancing is hard to do without downtime.
- Upsides of partitioning:
- High availability - If one box goes down, others still operate (albeit with partial data).
- Faster queries.
- More write bandwidth.
- Small datasets on each server help with caching.
- More options for balancing and optimization.
- No replication required.
Replication and Cloning
- App Layer Server Cloning
- Use templates to ensure each server is identical in codebase and configuration.
- Sessions are stored in a DB or Cache on another server.
- DB Layer Master/Slave Replication
- Provides redundancy and faster read times.
- For each master, there is a set of slaves that data is replicated to.
- Reads can be load balanced amongst the slaves.
- Writes go to a master then copied to slaves.
- If you scale further to the point of needing multiple masters to handle the volume of writes, then the writes need to be replicated to the rest of the masters as well, adding complexity.
- Using multiple masters also improves redundancy, in the case a master goes down.
Example Reference Architecture
- Users come from the Internet and hit the load balancer.
- LB routes to a webserver while also updating the cookie to specify which server this user should go to in the future.
- On the next request, the load balancer uses this cookie data to route to the same server so that state is maintained.
- Behind the web servers is a set of load balancers used to route reads to the DB slaves and another set of load balancers to route writes to the masters.
- Writes trigger a replication to each other master and then down to each of their slaves.
- For additional redundancy, scale out to multiple data centers to reduce risk of power failure or building failures.
- Perform load balancing at the DNS level to balance between data centers.
- Firewall strategy:
- Use firewalls to lock down ports. For instance only 80/443 into load balancers.
- The load balancers can then terminate SSL connections and pass on to port 80 to the web servers.
- Communicate to DB servers only on the port they need (e.g. 3306).
- This results in placing a firewall in front of each load balancer layer: in front of service tier, in front of data tier.